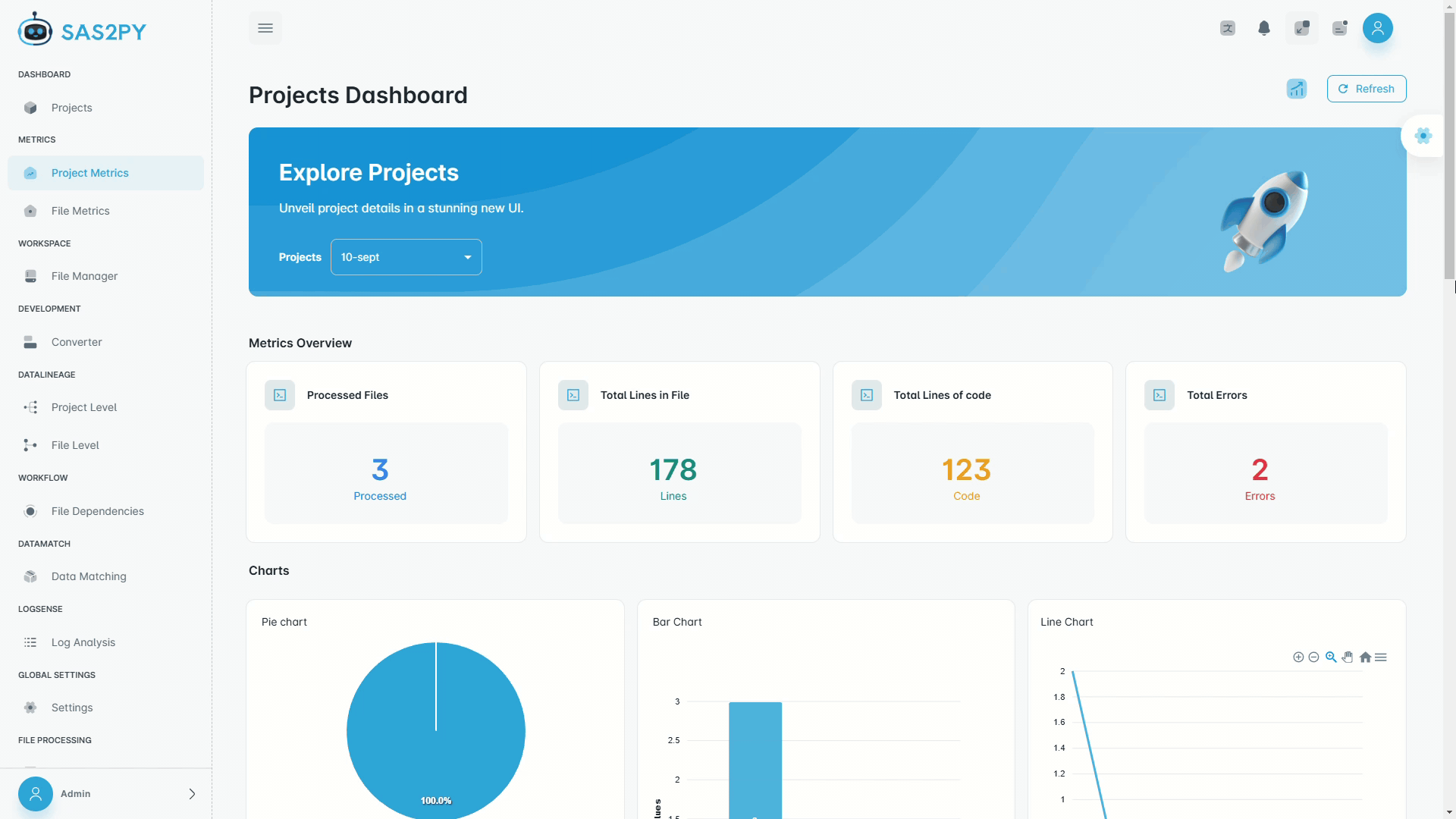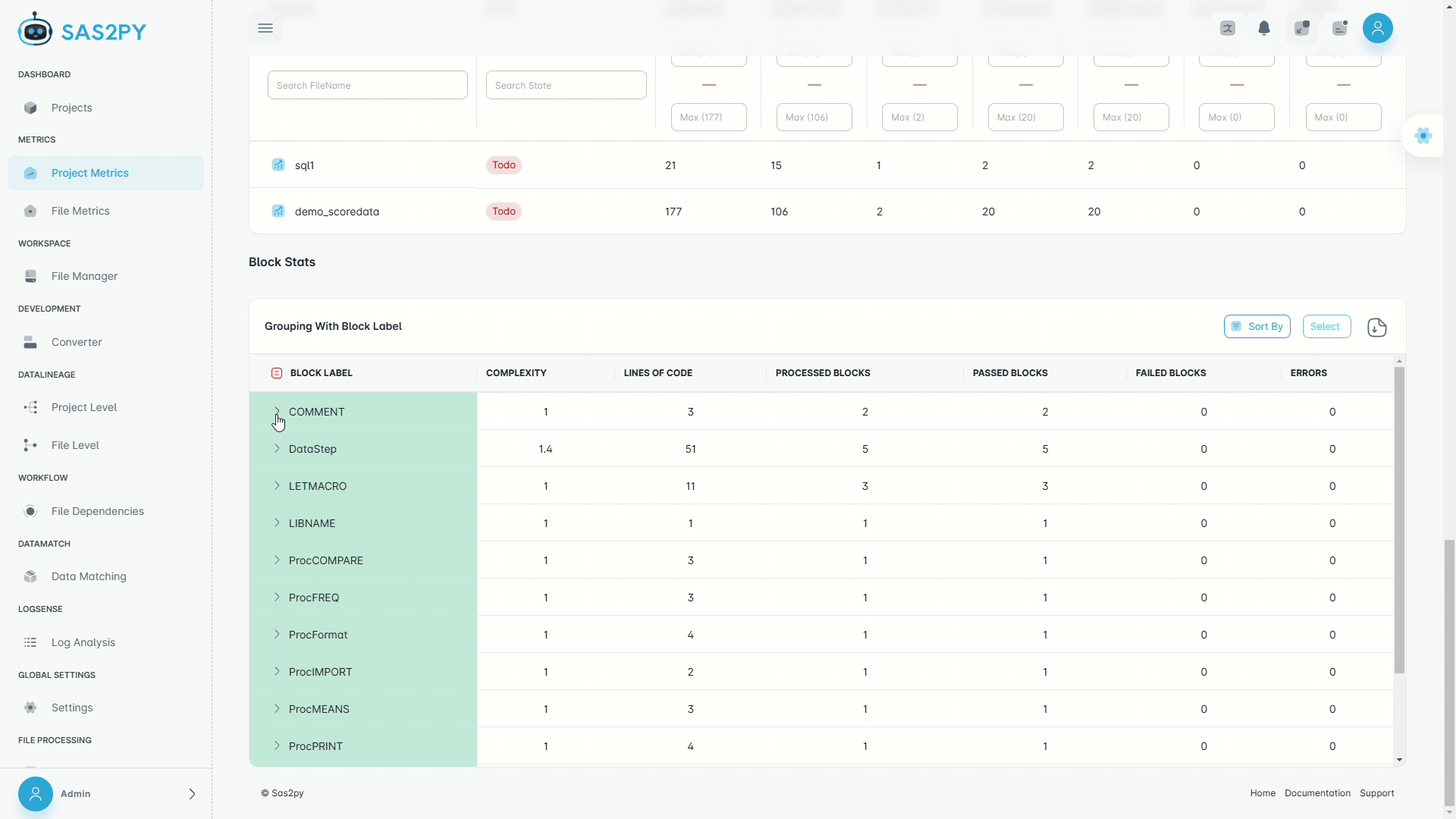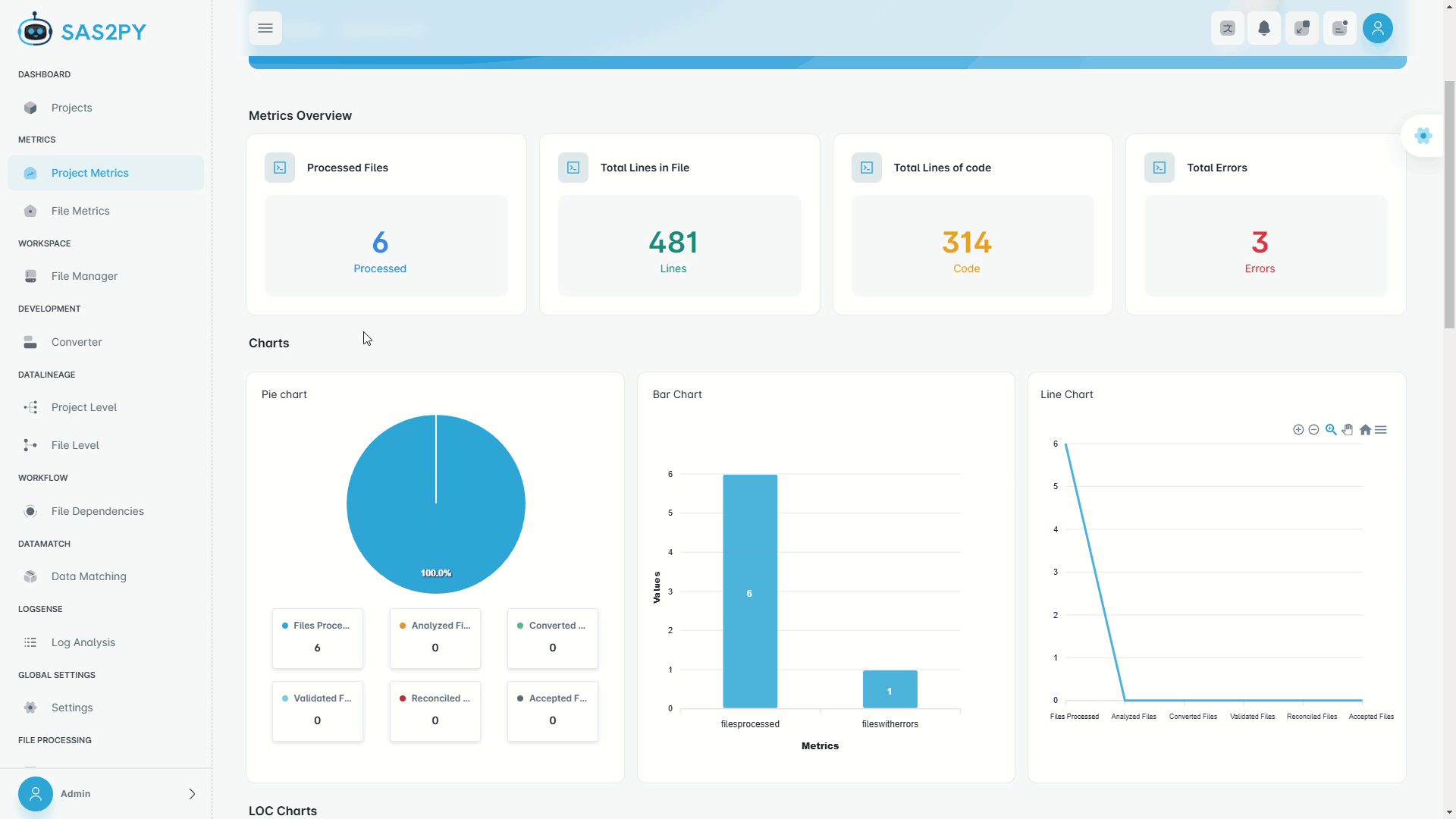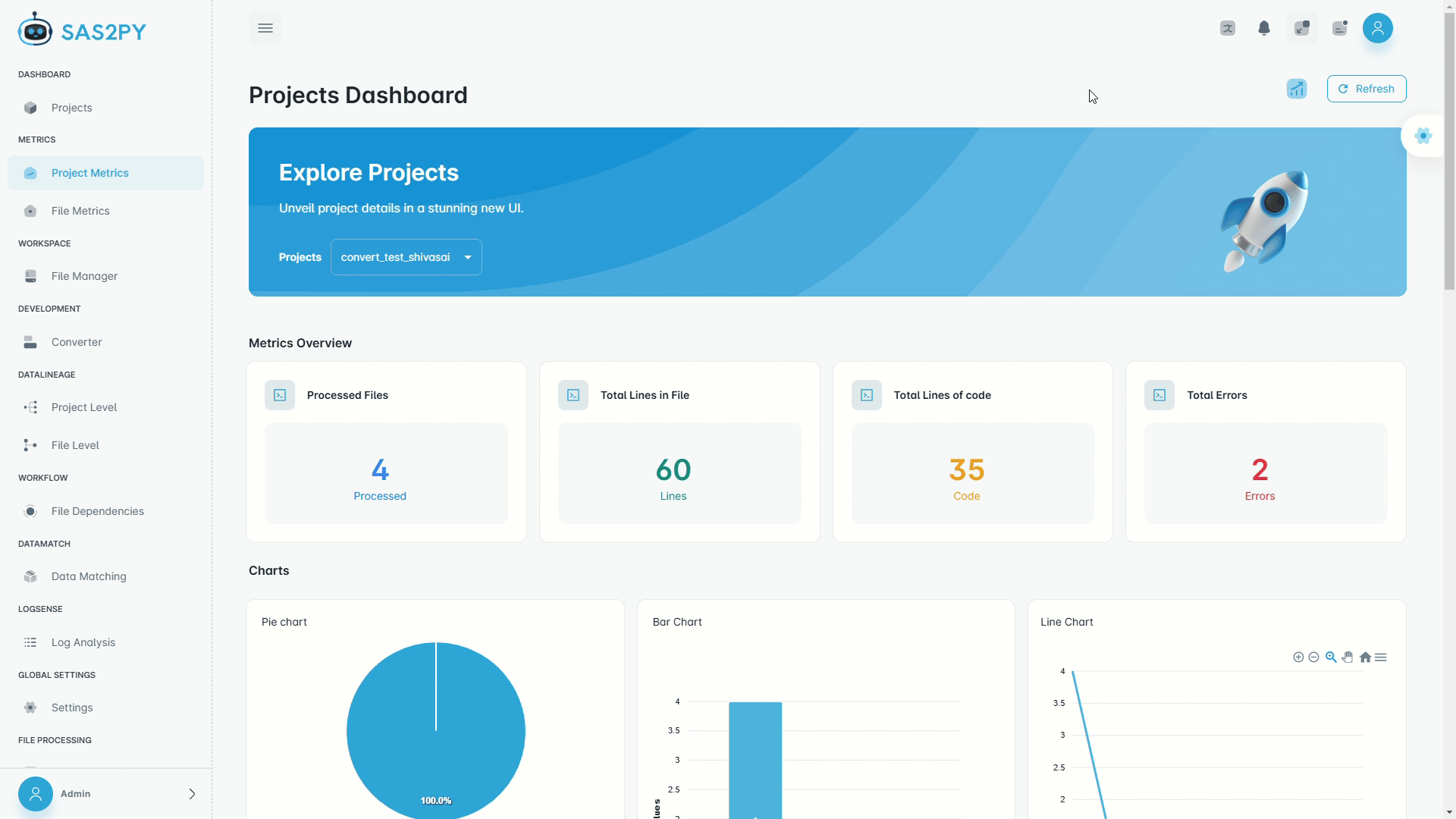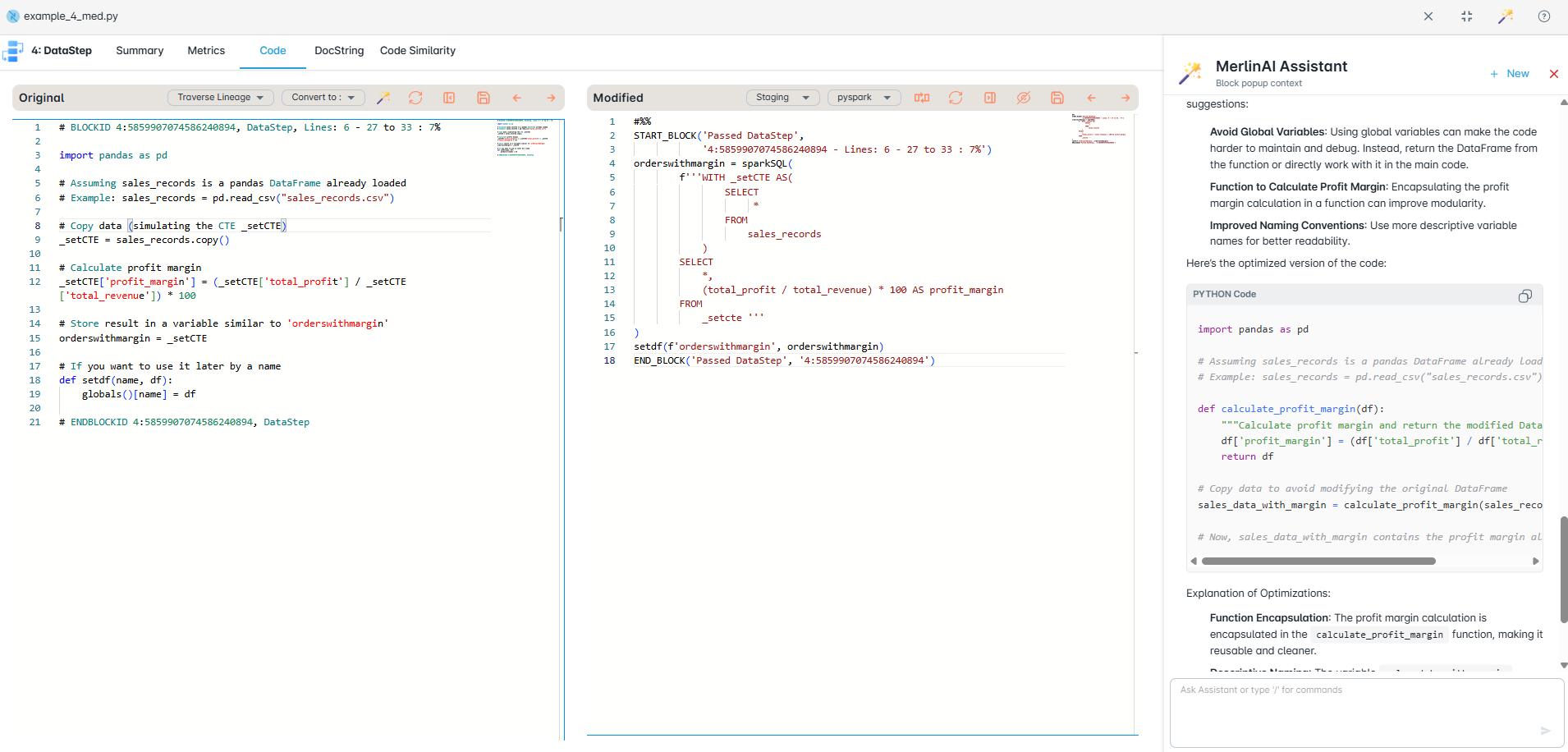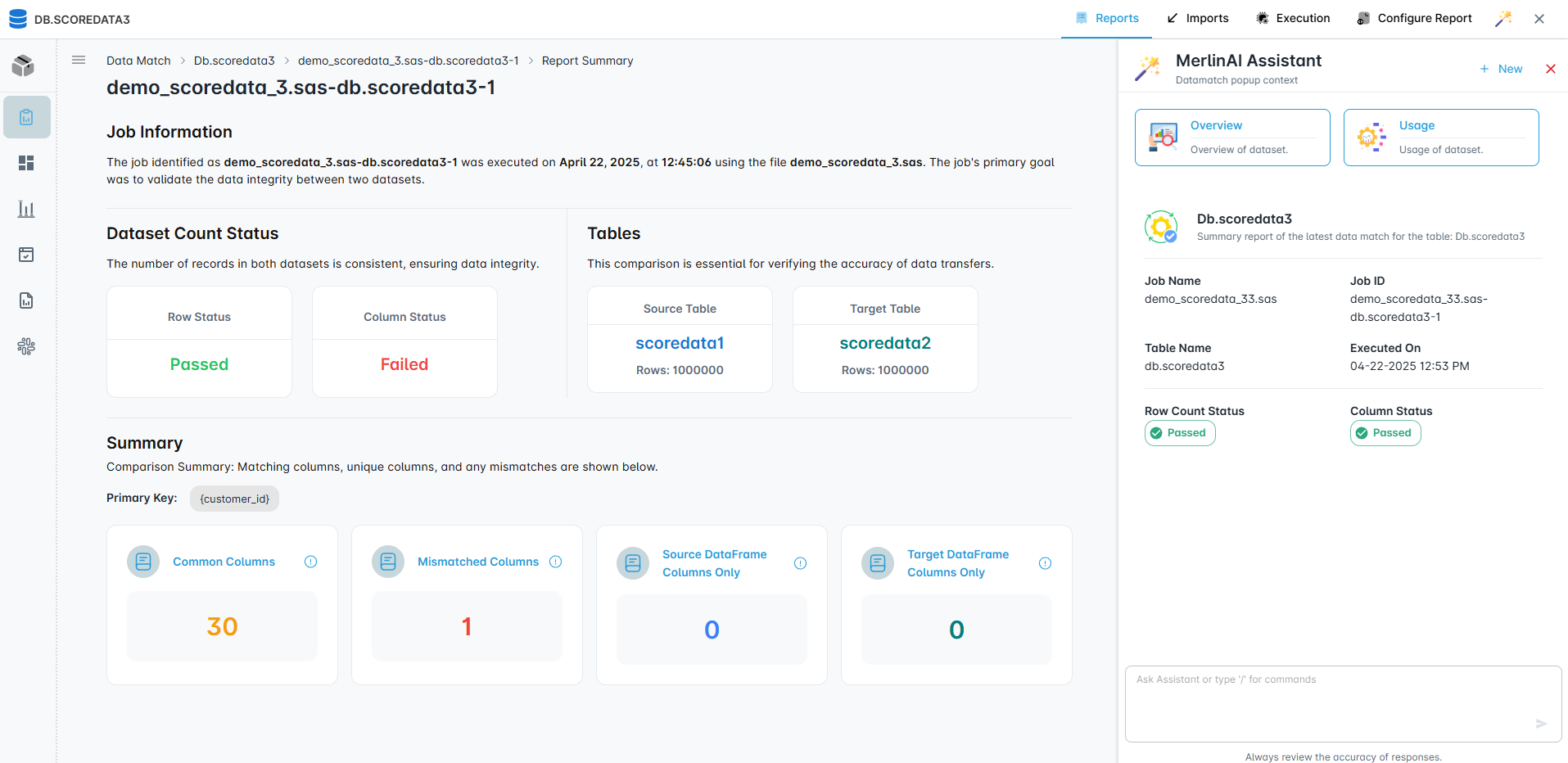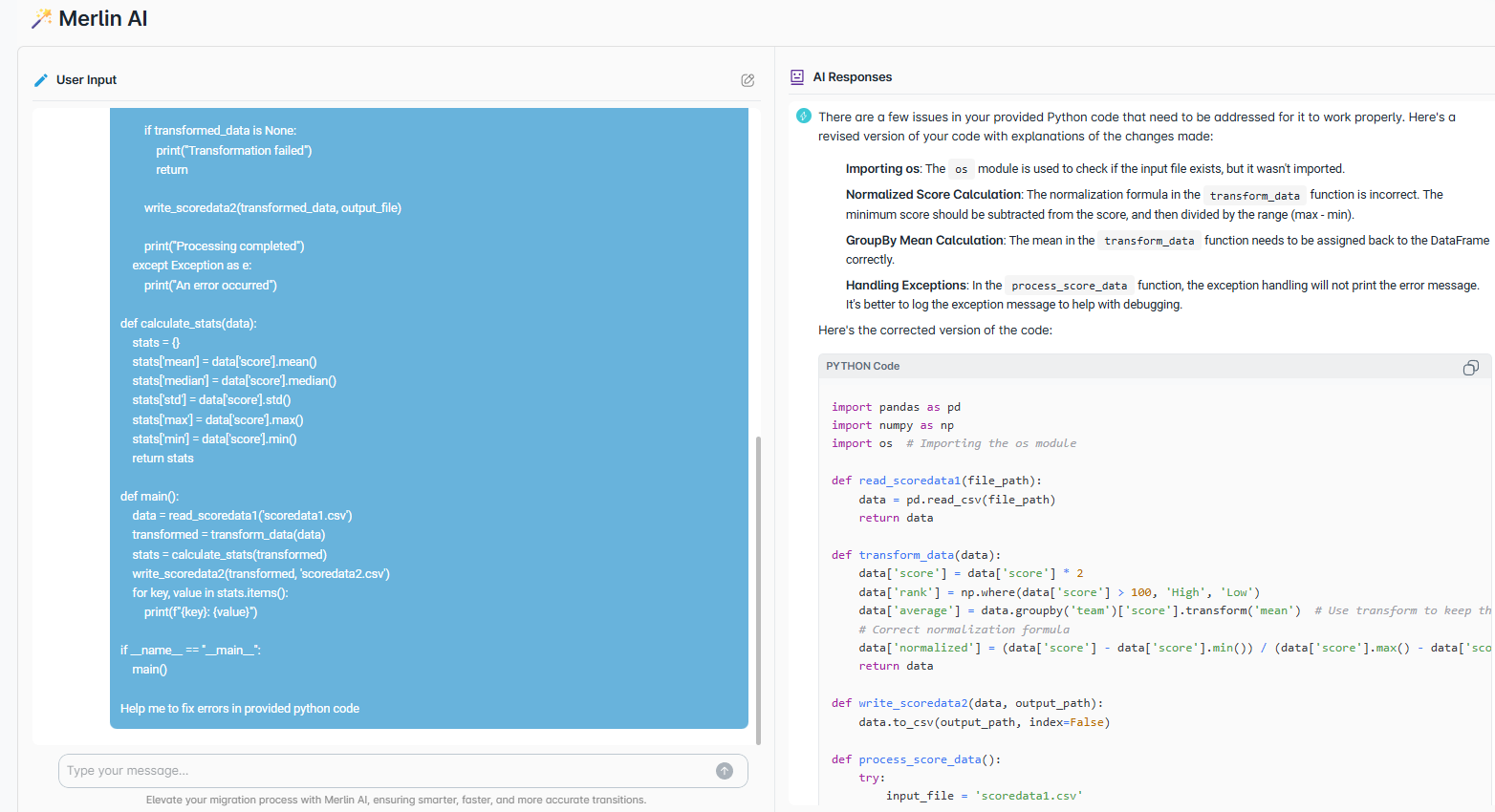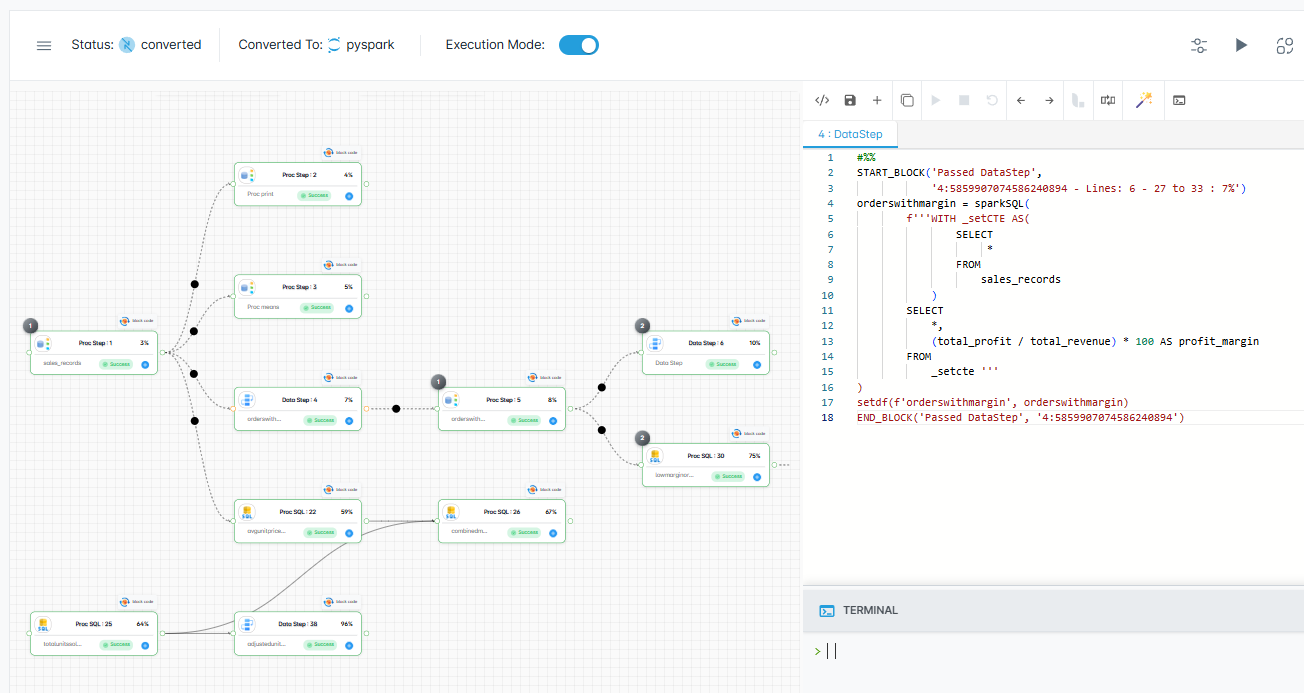
Analyze and Insights
- Automatic assessment of DataStage jobs and DSX/ISX assets for rationalization and migration planning
- Comprehensive dependency mapping with data and file lineage
- Development of required frameworks and standards
- Workflow complexity analysis, tool chains, and usage signals
- Rationalize and standardize DataStage ETL and job patterns